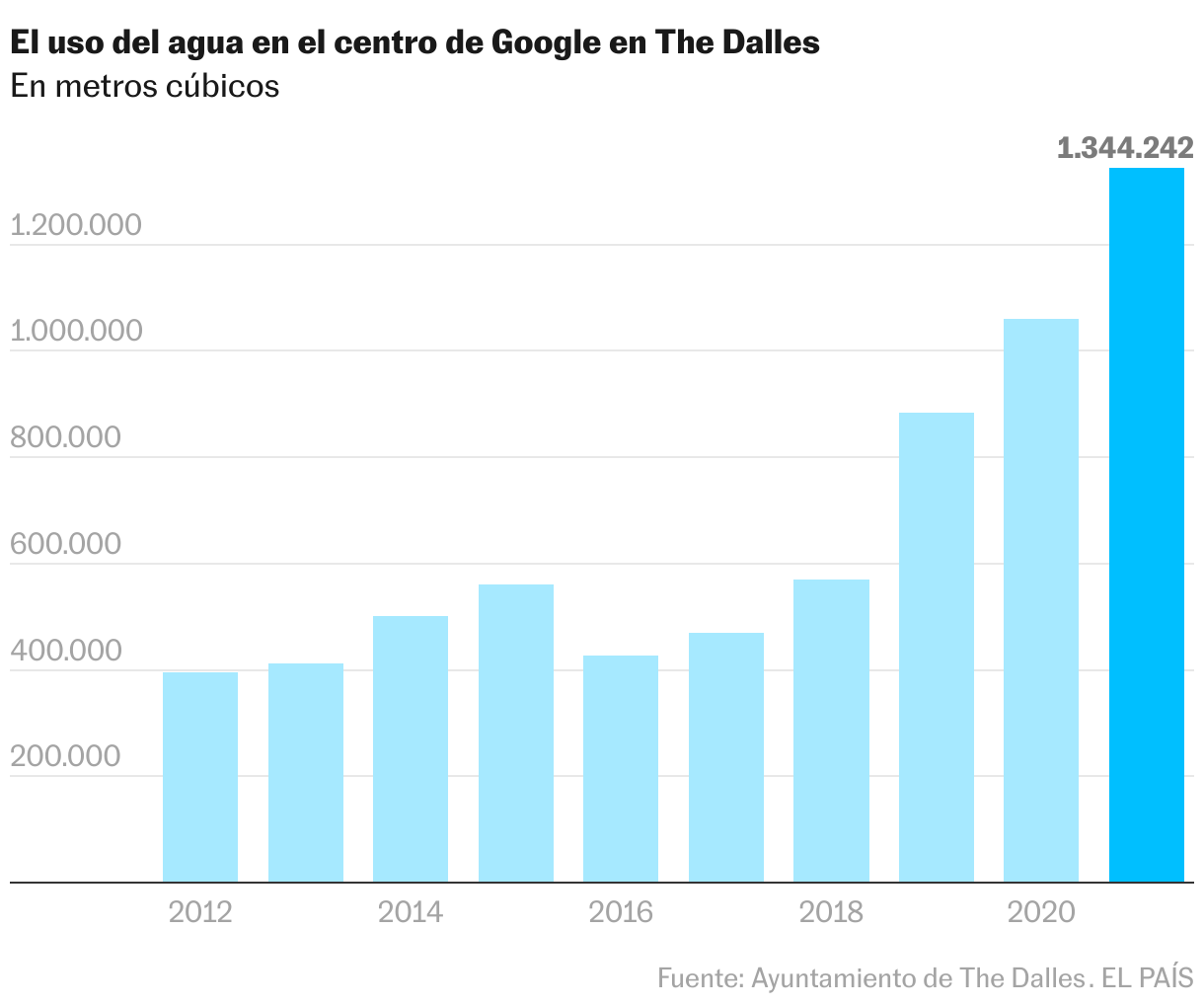
Los vecinos de The Dalles, un pequeño pueblo de Oregón, viven una paradoja. Pese a que la villa está a pie del caudaloso río Columbia, tiene un clima casi desértico: las precipitaciones son escasas y hace dos veranos se rozaron los 48 grados. La amenaza de las restricciones de agua pende sobre los 15.000 habitantes del pueblo desde hace tiempo. Por eso no les gustó enterarse a principios de año de que más de un cuarto del consumo total de ese preciado memorial se lo apunta un centro de datos de Google, que lo dedica a refrigerar las miles de computadoras que pueblan la infraestructura. Según ha podido examinar el medio almacén Oregon Live, la instalación ha triplicado su compra en el final quinquenio, y la multinacional tecnológica planea desobstruir dos centros de datos más en la cuenca del Columbia. Los ecologistas ya han experto de que eso podría afectar a la flora y fauna de la zona e incluso provocar escasez entre los granjeros y agricultores de The Dalles.
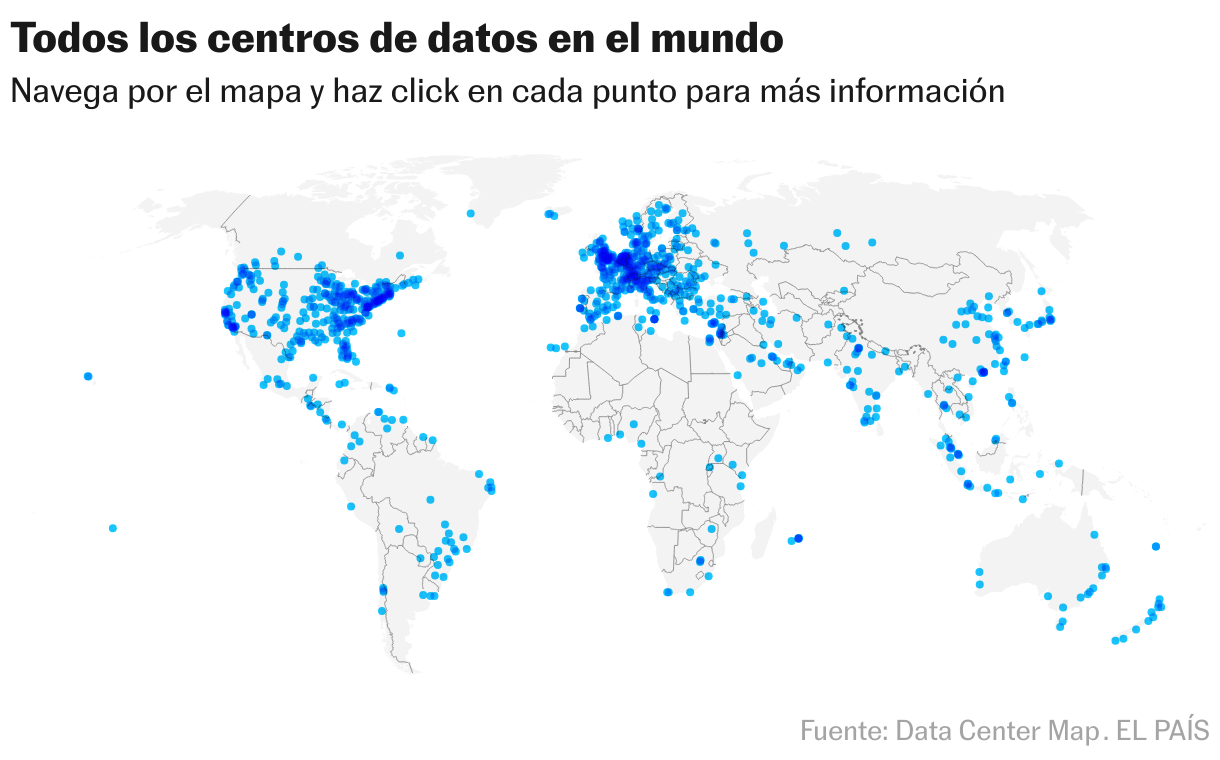
No es un caso accidental en Estados Unidos, país que concentra en torno al 30% de todos los centros de datos del mundo. Arizona, Utah o Carolina del Sur conocen perfectamente la insaciable sed de este tipo de infraestructura. Todavía lo saben en Países Bajos, donde Microsoft se vio envuelta el año pasado en un escándalo al conocerse que una de sus instalaciones consumía cuatro veces más de lo notorio en un contexto de sequía. O en Alemania, donde las autoridades de Brandeburgo negaron los permisos a Google para que construyera un centro de datos en la región al considerar que una gigafactoría de Tesla ya consumía demasiada agua.
Ver series en streaming, usar aplicaciones online (que no estén instaladas en el móvil) o asegurar fotos en la montón es posible gracias a una infraestructura mundial que consta de una gran fusión de centros de datos y de más de un millón de kilómetros de cableado. La creciente complejidad de las aplicaciones que se usan diariamente exigen más y más potencia de cálculo. Todo eso se traduce en legiones de ordenadores funcionando a máxima potencia día y confusión, cuyo consumo energético ya representa como leve el 2% del total mundial. Para que las máquinas no se sobrecalienten, hace error refrigerarlas. Se puede hacer con sistemas de ventilación, similares a los que usan los ordenadores personales, pero es más de lance suavizar los procesadores con agua.
La sed de las tecnológicas está en encumbramiento. El consumo de agua de Google aumentó un 20% en 2022, según cifras aportadas por la propia compañía. Y el de Microsoft, dueña de un 75% de OpenAI (los creadores de ChatGPT), lo hizo en un 34% en el mismo periodo. No se contemplan aquí los fortuna hídricos consumidos en la reproducción de la electricidad que alimenta los servidores ni en los procesos de fabricación del hardware. Amazon, que pegado a las dos anteriores controla casi la medio de los hipercentros de datos de todo el mundo (los que cuentan con más de 5.000 servidores), y cuya filial AWS lidera el mercado de la computación en la montón, ha preferido no aportar datos a este gaceta.
La futuro en importancia es Meta, matriz de Facebook, Instagram, WhatsApp o Messenger, que gastó en 2022 un 2,7% más. La compañía planea desobstruir uno de estos hipercentros de datos en Talavera de la Reina, que, tal y como avanzó EL PAÍS, consumirá más de 600 millones de litros anuales de agua potable. Fuentes de la empresa aseguran que el plan sigue delante y avanza al ritmo que le marcan las normativas competentes, si perfectamente las obras todavía no han empezado.
¿Cómo se explica esta súbita ataque del consumo de agua de las tecnológicas? ¿Por qué es beocio en Meta o Apple que en Microsoft y Google? El 4 de noviembre de 2022 se presentó ChatGPT, el bot conversacional que dio el pistoletazo de salida de la carrera por la inteligencia fabricado (IA) generativa. Google ya tenía grandes modelos de idioma similares, como LaMDA, en período positivo, pero no los había destapado al manifiesto. Para que estos modelos echen a encontrarse hay que entrenarlos ayer. Ese proceso exige que legiones de computadoras de entrada potencia (las GPU) procesen cantidades ingentes de datos día y confusión durante semanas o hasta meses para encontrar patrones en los textos que sirvan para poder articular luego fragmentos con sentido. En el caso de GPT-4, la lectura más descubierta hasta el momento de ChatGPT, ese entrenamiento se realizó en Des Moines, Iowa, poco totalmente desconocido por los vecinos hasta que un parada cargo de Microsoft dijo en un discurso que “se hizo textualmente al banda de campos de maíz de Des Moines”, según reportó The Associated Press.
El esfuerzo adicional por desarrollar grandes modelos de IA puede favor disparado el consumo de agua de Google y Microsoft, las dos tecnológicas que más válido han apostado por esta tecnología. Así lo cree el investigador Shaolei Ren, profesor asociado de ingeniería eléctrica y computacional de la Universidad de California, Riverside y doble en sostenibilidad de la IA. “No lo podemos proponer con certeza si las empresas no nos aportan datos concretos, pero el aumento de 2022 fue muy abultado respecto a 2021 y sabemos que en esa época invirtieron muy fuertemente en IA generativa, así como en otros servicios relacionados con la IA”, explica por correo electrónico. “La IA se ha integrado en casi todos los productos de uso diario de Microsoft y Google, incluyendo sus buscadores”.
Las compañías no ofrecen datos sobre cuánta agua y energía de más cuesta entrenar modelos de IA respecto al consumo habitual de los centros de datos. “Lo que sí sabemos, porque así me lo ha confirmado el director de una de estas infraestructuras, es que los chips usados en el entrenamiento de IA consumen mucho más que los de los servidores comunes”, destaca Ana Valdivia, profesora de Inteligencia Fabricado, Gobierno y Políticas del Oxford Internet Institute cuya investigación más fresco se centra en evaluar el impacto ambiental de la IA.
Ren publicará a finales de año pegado con otros tres colegas una investigación en la que ofrecen una guarismo estimada de cuánta agua cuesta chatear con ChatGPT. Por cada entre 5 y 50 prompts (preguntas o instrucciones), ChatGPT consume medio litro de agua. La horquilla de 5 a 50 está relacionada con la complejidad de los prompts. El cálculo contempla todo el agua usada durante el entrenamiento del maniquí, que es el momento de viejo consumo, y la empleada por la máquina para procesar las órdenes que se le dan la aparejo.
Las empresas afectadas ofrecen otros argumentos. Una portavoz de Google dice que el abultado brinco en el consumo de agua de 2022 “se corresponde al crecimiento del negocio”. La respuesta de Microsoft es casi calcada.
*META: Aunque el prominencia total de agua consumida ha descendido, la cantidad evaporada ha subido un 2,7%.
Otras grandes tecnológicas, como Meta (2,7%) o Apple (8,5%), han tenido un incremento en el consumo de agua, pero significativamente beocio que los de Microsoft y Google. Son gigantes empresariales y su actividad ha crecido, pero su postura por la IA no es tan entrada. Aunque esa tecnología está presente en sus aplicaciones, no tienen grandes modelos similares a ChatGPT (o como Bard, de Google, o Copilot, de Microsoft).
Cómo se consume el agua
Los centros de datos tienen el aspecto de naves industriales que constan de varias salas. En cada una de ellas hay hileras de racks, o torres de ordenadores de la mérito de un armario. Estas hileras están dispuestas en pasillos, de modo que los operarios puedan manipular los circuitos de cada máquina.
Los servidores emiten calor cuando funcionan. La concentración de tantos ordenadores en un mismo circunscripción hace que ese intención sea más intenso. Muchos centros de datos recurren a torres de refrigeración para evitar el sobrecalentamiento, el mismo sistema empleado en otras industrias. Se zócalo en exponer un caudal de agua a una corriente de céfiro en un intercambiador de calor, de forma que la evaporación enfríe el circuito.

Este método es más válido energéticamente que los enfriadores eléctricos, pero implica que una gran cantidad de agua se evapore (es proponer, que no vuelva al circuito). “Esa es el agua que figura como ‘consumida’ en los registros de las tecnológicas. Dependiendo de la temperatura extranjero del dilatación húmedo, una torre de refrigeración suele consumir entre uno y cuatro litros de agua (hasta nueve en verano) por cada kWh de energía del servidor”, lee el estudio de Ren.
En torno al 20% del agua utilizada en los sistemas de refrigeración (la que no se evapora) se vierte al final del ciclo en las plantas de aguas residuales. “Esa agua contiene grandes cantidades de minerales y sal, por lo que no puede dedicarse al consumo humano sin ser tratada ayer”, ilustra Ren.
Es difícil establecer cuál es el consumo medio de un centro de datos. Los que están en climas más fríos necesitan menos refrigeración que el resto. De la misma forma, la exigencia de agua es distinta en las épocas más calurosas del año que en las más gélidas. Necesitan, eso sí, usar agua limpia y tratada para evitar atascos o el crecimiento de bacterias en las tuberías. Cuando se emplea agua del mar o recuperada, hay que depurarla ayer de meterla en los sistemas de refrigeración. En el caso de Google, casi el 90% de su consumo en EE UU procedió de fuentes potables, asegura Ren.
La ubicación importa
Los centros de datos solían estar en las ciudades, pero las crecientes evacuación energéticas de estas infraestructuras las han expulsado del entorno urbano, incapaz de abastecerlas. “Necesitan igualmente una ubicación segura, que cuente con un suministro estable de electricidad y que no tenga peligro de catástrofe climática. Por todo eso, en las últimas dos décadas se han ido a la periferia”, explica Lorena Jaume-Palasí, fundadora de Algorithm Watch y The Ethical Tech Society y asesora de ciencia y tecnología del Parlamento Europeo.
“Los centros de datos modernos son muy extensivos. Se suelen ubicar cerca del desierto o en zonas agrarias para poder explayarse en extensión: es habitual que se monten y muevan módulos de servidores según las evacuación”, indica. Un estudio cuidado por investigadores de Virginia Tech estima que una casa de campo parte de los centros de datos de EE UU consumen agua de cuencas con un estrés hídrico moderado o parada, zonas donde suele favor disponiblidad de energía solar o eólica.
Aurora Gómez, del colectivo Tu Estrato Sequía Mi Río, nacido como reacción al megacentro que Meta construirá en Talavera de la Reina, ve un patrón detrás de estas actuaciones. “Las empresas suelen ir a inquirir para sus centros de datos zonas despobladas y con altas tasas de paro para que haya poca contestación social”, reflexiona.
Un problema sin perspectivas de decisión
La industria está apostando de forma clara por integrar la IA en cada vez más productos y servicios. ¿Hay forma de entrenar modelos de IA sin comprar grandes cantidades de agua? Ren cree que no. “Se podrían usar secadores eléctricos para refrigerar los ordenadores, pero tienen un gran compra energético, por lo que aumentaría mucho el consumo de agua implicado en la reproducción de electricidad. Sobre el papel se puede no usar agua en el proceso, pero lo veo muy difícil”, concluye el docente.
Eso es lo que defienden las empresas, inmersas en planes de mejoras de eficiencia de sus sistemas. Según fuentes de Meta, los nuevos centros de datos que planea desarrollar la compañía especialmente enfocados a la IA usarán sistemas de secado eléctricos, que no necesitan agua (más allá de la necesaria para gestar electricidad). Un fresco estudio de Javier Farfan y Alena Lohrmann, en el que se tienen en cuenta los datos de consumo actuales y las perspectivas de crecimiento crematístico, Europa necesitará a partir de 2030 más de 820 millones de metros cúbicos de agua anuales solo para que podamos usar internet.
Algunas voces empiezan a hacer llamamientos para que usemos menos las herramientas digitales. La idea de fondo es la misma que con el transporte o el consumo de carne: la única forma efectiva de revertir la crisis climática es deducir los niveles de producción y consumo. Eso es lo que sostienen las teorías del decrecimiento.
Valdivia no cree que el decrecimiento digital sea la decisión. “Me parece que responsabilizar a la gentío de ese consumo es el enfoque falso. Por otra parte, los centros de datos son mucho más bártulos y necesarios socialmente que, por ejemplo, los coches eléctricos. Hay alternativas a la movilidad: puedes dejar el coche y coger el autobús o el tren. Pero no hay alternativa a los centros de datos”.
Puedes seguir a EL PAÍS Tecnología en Facebook y X o apuntarte aquí para acoger nuestra newsletter semanal.
Suscríbete para seguir leyendo
Lee sin límites
_
Creditos a Manu González Pascual
Fuente

